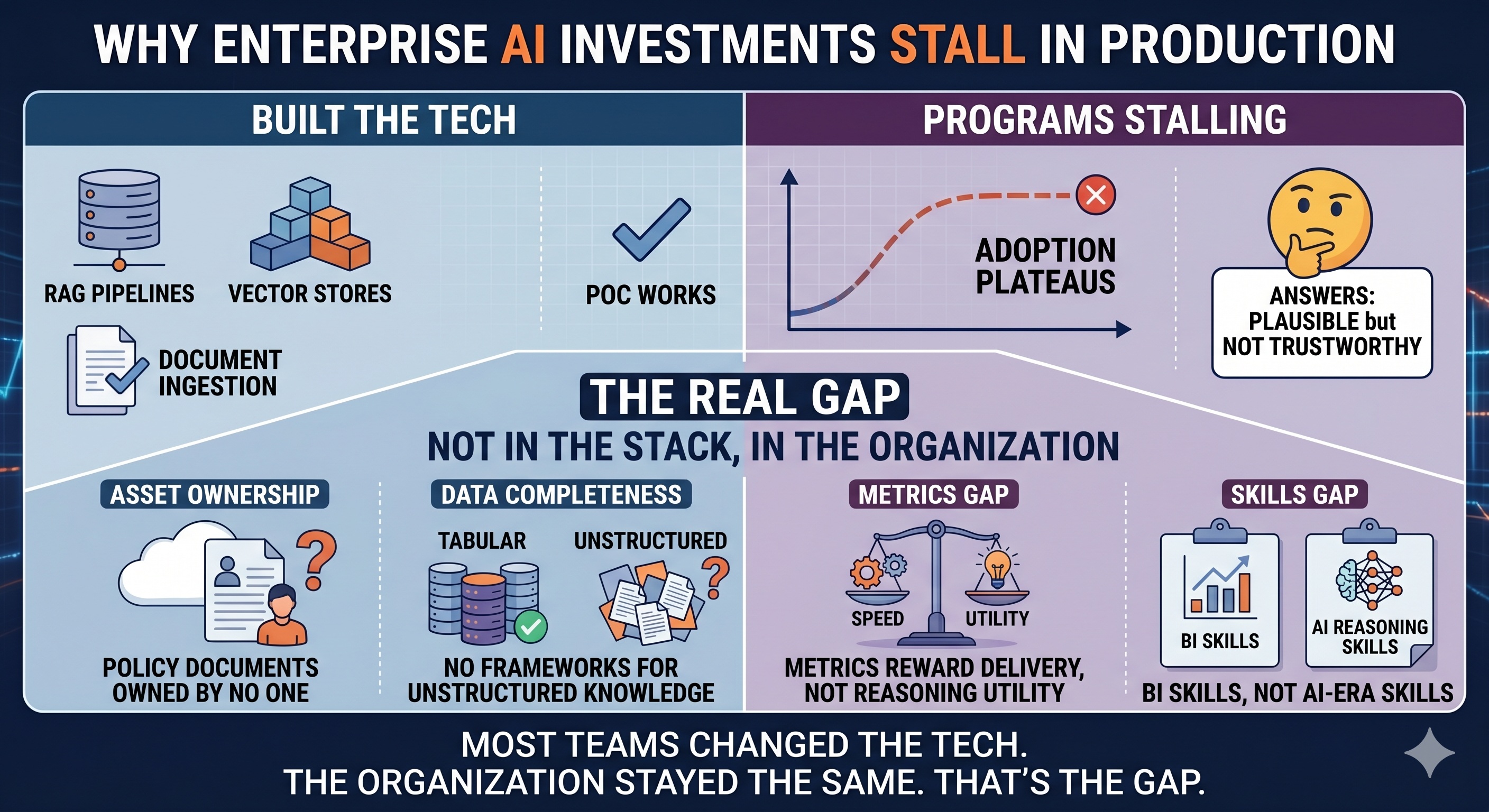
- Enterprise AI programs that stall in production typically have an organizational problem, not a technical one — the stack evolved faster than the function designed to operate it.
- The Four Organizational Gaps — Ownership, Completeness, Metrics, and Skills — are the under-diagnosed causes of AI programs that succeed in proof of concept and fail at scale.
- Unstructured knowledge assets require the same stewardship discipline that structured data earned a decade ago: explicit owners, defined update cadences, and version control.
- Without instrumentation at the reasoning layer, the data function's metrics dashboard will show green while business outcomes quietly degrade.
- The skills required to build a reasoning-ready knowledge layer — epistemic curation, disambiguation authoring, exception documentation — are absent from most enterprise job descriptions and cannot be substituted by improving the model.
Three years into serious enterprise AI investment, most organizations have done the right things technically. RAG pipelines are live. Vector stores are provisioned. LLMs have been pointed at the data warehouse, and document ingestion runs nightly. The proof of concept succeeded—it almost always does. Funding was secured. Roadmaps turned green.
Then production happened.
The model's outputs looked plausible. They weren't trustworthy. Adoption stalled—not with a clean failure event, but quietly, in the gap between "this works in the demo" and "I'll act on this." Teams investigated. The architecture, on close inspection, was sound. So they changed the architecture anyway—better chunking, a different embedding model, a new retrieval strategy. Outputs improved at the margin. Adoption stayed flat.
The CFO still won't base a capital ratio calculation on it. The clinical team won't let it near a prior authorization workflow. The M&A diligence team treats it as a search engine with a conversational interface—not a reasoning tool. These are not fringe failure modes. They are the median outcome of enterprise AI programs at the end of 2025.
The uncomfortable answer—the one that rarely surfaces in vendor conversations or architecture reviews—is that the problem was never in the stack. The enterprise AI readiness gap that prevents programs from scaling is organizational, not technical. And because it is organizational, it does not appear in a system diagram, an RFP evaluation matrix, or an implementation timeline.
The enterprise AI readiness gap isn't a technology problem wearing an architecture disguise. It's an organizational problem that the architecture review was never designed to find.
A Framework for What's Actually Missing: The Four Organizational Gaps
Before diagnosing any specific failure, it helps to name the four axes along which enterprise organizations are consistently under-prepared. We call this framework The Four Organizational Gaps. Each gap is distinct, each is diagnosable, and none of them will be resolved by switching models or adjusting retrieval parameters.
The four are: the Ownership Gap, the Completeness Gap, the Metrics Gap, and the Skills Gap. Together, they describe why an organization's knowledge layer—the unstructured policies, procedures, exception rules, and institutional reasoning that AI must work with—remains unready to support production AI, even when the technical layer is mature.
This is not a diagnosis of technical immaturity. The organizations stalling are often the ones that moved earliest and invested most. It is a diagnosis of organizational lag—the architecture evolved faster than the function that was supposed to operate it.
Gap One: The Ownership Problem Nobody Assigned
Tabular data has stewards. Unstructured knowledge does not.
Every CFO knows who owns the chart of accounts. Every data leader can name the steward of the customer master. Tabular data—the kind that flows through ERP, CRM, and the warehouse—has assigned ownership, defined update cadences, and documented lineage. That infrastructure exists because BI demanded it a decade ago.
The policy documents, procedure manuals, underwriting guidelines, and clinical protocols that AI must reason over have no equivalent stewardship. Consider a hospital system's prior authorization rules: they may be maintained by a compliance officer, updated by legal, overridden by a regional VP, and stored across four SharePoint folders—with no single authoritative version and no defined owner accountable for keeping the AI-consumed copy current.
In a monthly close workflow, this surfaces fast. The AI assistant confidently cites a revenue recognition policy that was superseded six months ago. The output isn't wrong because the model failed—it's wrong because no one was responsible for keeping the knowledge asset current. The retrieval system retrieved exactly what it was given. The deeper problem is that AI doesn't understand your business—it understands the version of your business that was last documented.
The fix isn't technical. It is the assignment of knowledge stewardship—explicit ownership of every document class that AI reasons over, with defined update cadences, version control, and a person accountable for currency and completeness. The same discipline BI demanded of structured data, applied to unstructured knowledge.
Gap Two: No Completeness Standard for the Knowledge Layer
For tabular data, completeness is measurable. Null rates, referential integrity, schema conformance—these are standard quality dimensions with defined thresholds and tooling. A CFO will not certify a close until the completeness metrics pass.
For unstructured knowledge, no equivalent standard exists—and the absence is quietly catastrophic.
Consider what AI must work with in a conglomerate's capital allocation review: board-approved investment criteria, subsidiary performance covenants, intercompany transfer pricing policies, and a history of exception approvals. These documents exist. But are they complete? Do they cover every scenario the model will be asked to reason over? Do they contain the edge cases, the "unless X" conditions, the regional carve-outs that experienced analysts carry in their heads but procedures do not state?
Most organizations treat document ingestion as a one-time migration task, not an ongoing quality function. The result is a corpus that is technically populated and epistemically incomplete—it answers common questions confidently and fails on the exceptions that matter most. And because there is no completeness scorecard for knowledge, the gaps are invisible until a decision goes wrong.
Building a Knowledge Completeness Standard—defined criteria for coverage, currency, disambiguation, and exception documentation—is the unglamorous work that determines whether an AI program can scale beyond the scenarios it was tuned on. Finance organizations that have done this for their month-end close have reduced close cycle time measurably; those that have not find the model useful for queries it saw in training and unreliable on anything adjacent.
Gap Three: Metrics That Reward Delivery, Not Reasoning
Ask any data function leader what metrics their team is held to. The answers are consistent: pipeline uptime, data freshness, ticket SLA, model accuracy on labeled test sets. These are the metrics of a BI-era function—optimized for delivering data to consumers, not for enabling machines to reason over it in production.
None of these metrics capture reasoning utility: whether the knowledge layer actually supports the decisions AI is being asked to make.
A credit limit check that returns the right answer 92% of the time on test data may perform at 60% in production if the knowledge corpus doesn't cover the exception categories that arise in real workflows. The pipeline is fresh. The accuracy metric is logged. The business outcome is broken. The data function's dashboard is green.
The missing instrument is something like reasoning coverage—the proportion of real production queries that the knowledge layer supports with sufficient, current, unambiguous context. Instrumented correctly, this would surface the Ownership Gap and the Completeness Gap automatically. But it requires measuring at the reasoning layer, not the delivery layer—a reorientation that most data functions have not made, because it was never required before.
The explainability and trust gap in enterprise AI adoption is downstream of this: when reasoning quality is not measured, it cannot be improved, and the AI system cannot earn the trust it needs to be used.
Gap Four: BI-Era Job Descriptions for an AI-Era Function
Pull the job description for a Senior Data Engineer or a Data Governance Manager at most enterprises. The competencies are consistent: SQL proficiency, dbt, data modeling, pipeline orchestration, metadata management. These are the skills that built the BI layer—and they remain important.
They are not the skills required to build a reasoning-ready knowledge layer.
The skills needed are different in kind. Four stand out:
- Epistemic curation — the ability to assess whether a document corpus covers a reasoning domain with sufficient depth and precision. This is analogous to a subject-matter expert reviewing a knowledge base for gaps, not a data engineer reviewing a schema for nulls.
- Disambiguation authoring — the ability to rewrite ambiguous policy language into AI-parseable prose without losing legal precision. A policy that says "subject to management discretion" is fine for a human reader and useless for a reasoning system.
- Exception documentation — the skill of making tacit institutional knowledge explicit: capturing the "unless X" conditions and regional carve-outs that experienced practitioners know but procedures do not state.
- Reasoning-layer QA — testing knowledge retrieval under adversarial and edge-case conditions, not just against a labeled test set built from the easy queries.
These competencies sit at the intersection of subject-matter expertise, technical literacy, and editorial judgment. They are not on most job descriptions. They are rarely in a BI-era team's skill inventory. And they cannot be outsourced to the model itself—the model can only reason over what it is given.
The Organizational Gap at a Glance
The contrast between the BI-era data function and what the AI era actually requires is not subtle. The table below makes the delta visible—and makes clear why retrofitting AI onto an unchanged organizational structure produces the outcomes that most enterprise programs are now experiencing.
| Dimension | BI-Era Data Function | AI-Era Data Function |
|---|---|---|
| Primary asset | Structured tables, schemas | Structured tables + reasoning-ready knowledge corpus |
| Ownership model | Data stewards per domain | Data stewards + knowledge stewards per reasoning domain |
| Completeness standard | Schema conformance, null rates | Schema conformance + reasoning coverage |
| Primary metrics | Pipeline uptime, data freshness | Delivery metrics + reasoning utility instrumentation |
| Key skills | SQL, dbt, data modeling, pipeline | + Epistemic curation, disambiguation authoring, exception documentation |
| Governance cadence | Schema changes, lineage tracking | + Document versioning, policy currency audits |
What This Means for Enterprise AI Investment
For a CFO or CIO evaluating an AI program that has plateaued, The Four Organizational Gaps offer a diagnostic lens that architecture reviews don't. Before authorizing another round of stack investment, the more productive questions are:
- Who owns each document class that AI reasons over, and what is their defined update cadence?
- Does the organization have a formal standard for knowledge completeness—and is anyone measuring it?
- Are the data function's metrics instrumented at the reasoning layer, or only at the delivery layer?
- Do the current job descriptions and team competencies cover epistemic curation and exception documentation—or only the skills the BI era required?
In finance, this manifests as the difference between an AI that can explain a journal entry and one trusted enough to support the monthly close—because the close requires reasoning over intercompany policies, exception approvals, and multi-entity consolidation rules that are almost never documented in the AI-consumed layer.
In healthcare, it separates a tool that handles standard prior authorization queries from one that can be trusted on complex cases—where the edge cases are precisely the ones that matter most and consume the most physician time.
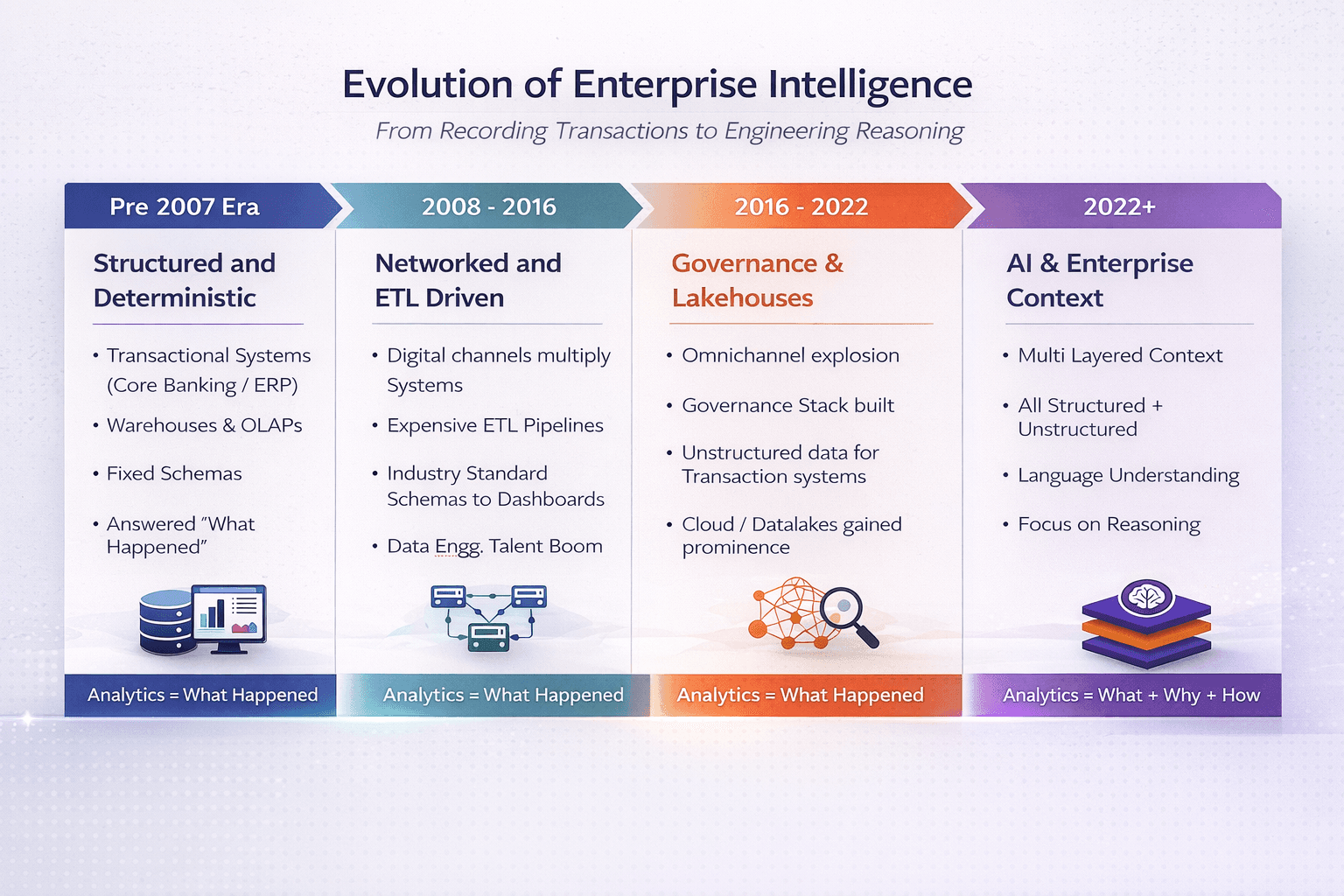
In conglomerates managing M&A diligence or distributor claims, it determines whether AI augments the senior analyst or remains a search tool with a better interface. The evolution of enterprise intelligence has always required the organization to evolve alongside the technology—and the AI era is no different in that respect, only faster.
The architecture can be correct and the program can still fail. The gap is organizational. It requires organizational answers—assigned ownership, defined standards, reoriented metrics, and a skills inventory built for reasoning, not just delivery.
Enterprise AI programs are not failing because organizations chose the wrong model or misconfigured their retrieval pipeline. They are failing because the investment thesis was framed as a technology problem when the harder constraint was always organizational.
The policy documents are unowned. The knowledge corpus has no completeness standard. The metrics dashboard is green because it measures the wrong things. The team that could fix it doesn't have a mandate—and often doesn't have the skills—because the job descriptions were written for a different era and nobody has yet updated them.
Closing that gap does not require a new vendor or a new model. It requires a leadership decision to treat the knowledge layer with the same rigor that the data layer earned when BI was the frontier. That decision is the one most enterprise AI roadmaps are still missing.
The architecture has evolved. The organization has not. Closing that gap is not an engineering task—it is a leadership one.