
Article
Feb 24, 2026
Enterprise intelligence has evolved from transaction recording to architectural reasoning. This article traces how structured systems, ETL-driven analytics, and governance stacks shaped decision-making - and why AI now demands a fundamental shift towards an enterprise context layer that makes “why” computational, not manual.

Pre-2007 – When Business Was Structured and Periodic
In the late 1990s and early 2000s, enterprises digitized operations at scale:
Banks implemented core banking systems.
Corporates implemented ERPs (SAP R/3, Oracle Financials, PeopleSoft).
These systems had a precise mandate: record transactions accurately.
So, analytics naturally followed the same model: Data warehouses, OLAP cubes, Dimensional models (Kimball / Inmon)
Since most businesses were unidimensional - products were finite, channels were controlled, processes were periodic, this worked. However, two structural limitations were embedded from the beginning:
We never expected systems to answer “why”. We built dashboards that counted, sorted, and summarized, but we never expected them to explain. Given the relative simplicity of operations, human reasoning sufficed.
Second was that we defined “data” too narrowly. The rows. The columns. The transactions. Everything else – Policy documents, product catalogues, operational SOPs, regulatory notes, consultant reports were left outside.
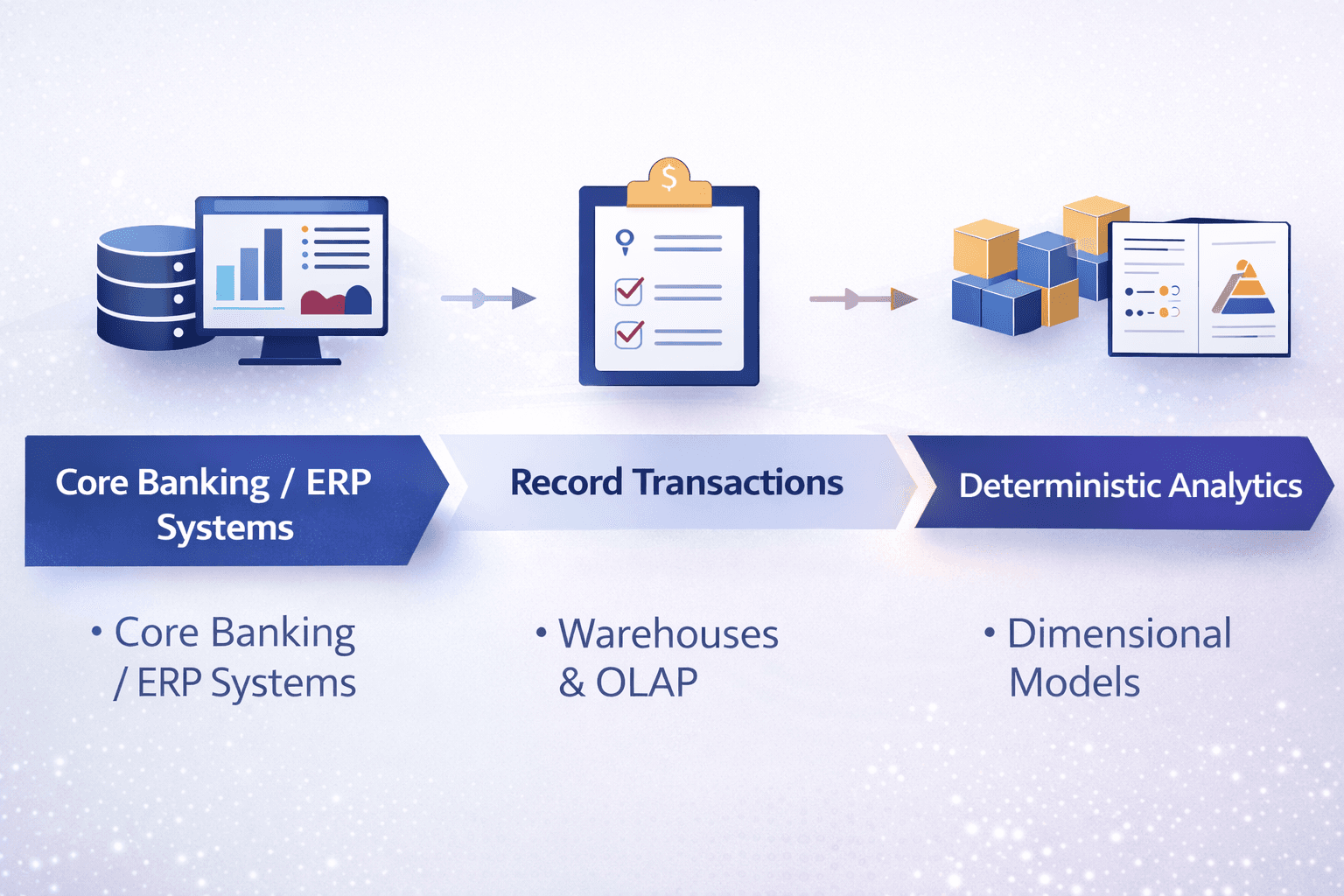
Eventually we were left with “Deterministic” systems – Predefined schemas, queries, and report / dashboard templates and analytics meant summarizing history
2008–2016 – Digital Channels Multiply the Enterprise
Around 2008, the operating model changed. Digital and mobile channels were introduced across industries, leading enterprises to deploy specialized systems:
Distributor Management Systems
Order Management Systems
Loan Management Platforms
Trade Finance Systems
Channel-specific applications
The enterprise stopped being one system of record and became a network of operational systems.
None of these systems spoke to each other – Each system maintained its own ledger. Data flowed upward in aggregated form into ERPs or core systems. But business questions evolved to understanding behaviour, customer, employee and money.
As the storage choice of relational warehouses had already been made in the previous era, Industry experts (SMEs) designed standardized schemas, dashboards and metric frameworks. On paper, this appeared powerful – domain knowledge codified into structured reporting.
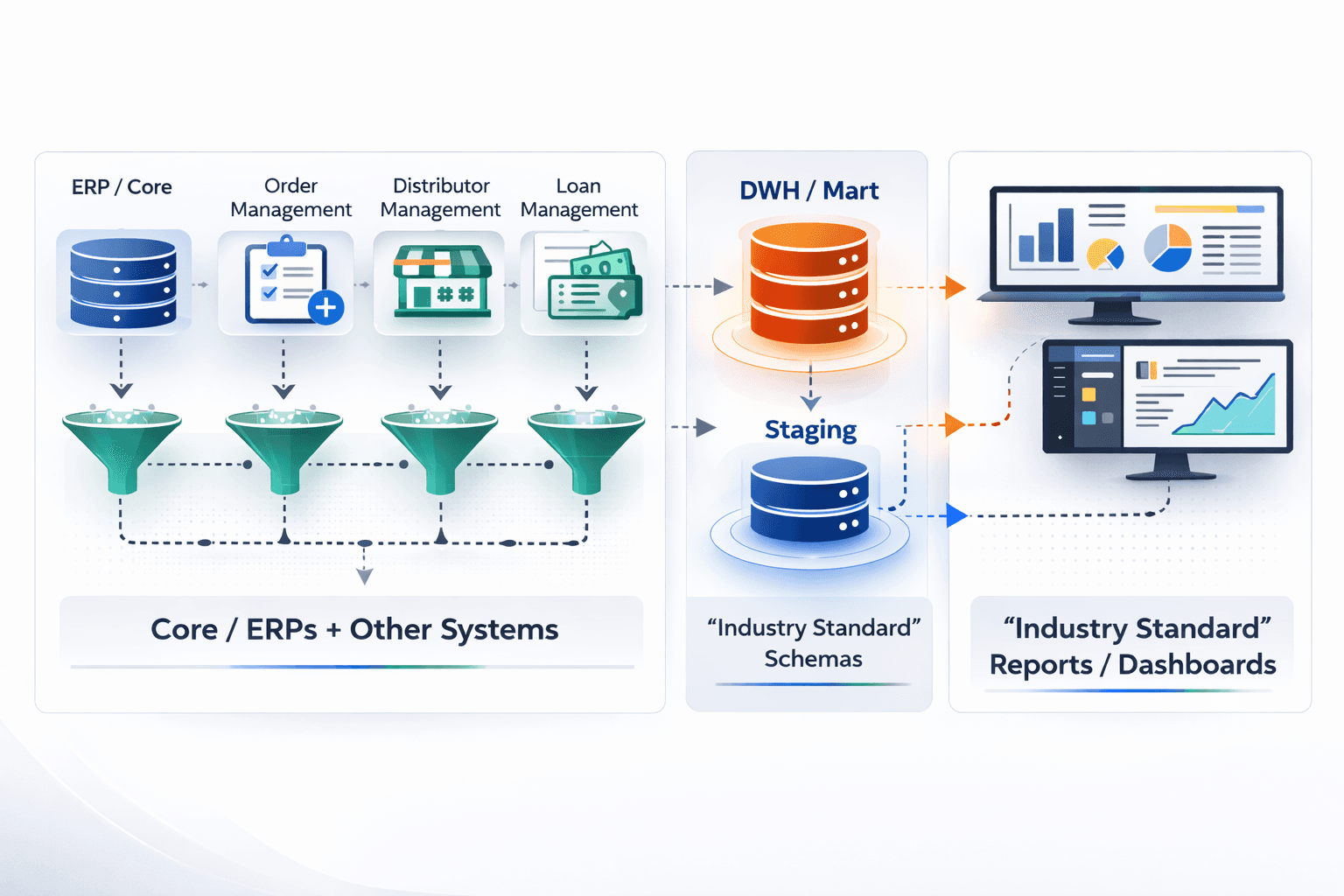
A difference in shape of data in upstream systems required massive piping efforts between upstream schemas and analytical schemas – creating a new ETL era: Operational schemas → transformed → analytical schemas
But three structural stresses emerged:
ETL pipelines became fragile in dynamic business environments.
Data engineering costs escalated as talent was required to constantly maintain transformations.
“Industry standard” models rarely translated cleanly into real operating complexity.
During this same period, tools to imagine future were introduced for localized forecasting, stress testing, cohort analysis, churn modelling etc. and created a new whitespace for quants and statisticians.
The choices might not be “mistakes” but more of make do with what's available - during this period compute was expensive. RDBMS architectures were dominant, Object storage was still nascent. Enterprises optimized within these constraints. Yet gradually, business logic ownership drifted away from business in the form of Sql Queries to technology teams. Translation became an ongoing burden.
2017–2022 – CXO Bandwidth Stretched
Digital payments, UPI, D2C commerce, quick commerce, digital marketing — operational complexity accelerated dramatically.
Business expanded across dimensions: channel, region, customer segment, product variation, partner ecosystem.
Questions evolved from:
“What happened?”
To:
“Why did collections weaken in specific regions?”
“What changed in conversion after that pricing update?”
“What shifted in behavior post that campaign?”
With CXOs losing control, Two parallel industries emerged:
1) Information Hunters: Analysts, Chiefs of Staff, data teams spent days reconstructing context:
Cross-referencing reports
Searching email trails
Tracking who changed what and when
Rebuilding logic manually
Time was spent assembling context rather than interpreting it.
2) Trust Infrastructures: Data quality tools, governance layers, lineage systems proliferated.
We have all seen it in the board meeting where two departments show two different numbers for the same metric, and hours disappear into debating the data instead of the decision.
CXOs understood that interpretation passed through multiple layers: ETL → Warehouse → Aggregations → BI → Exports → Analyst Interpretation. Each layer subtly altered meaning, they started looking for backups to build trust.
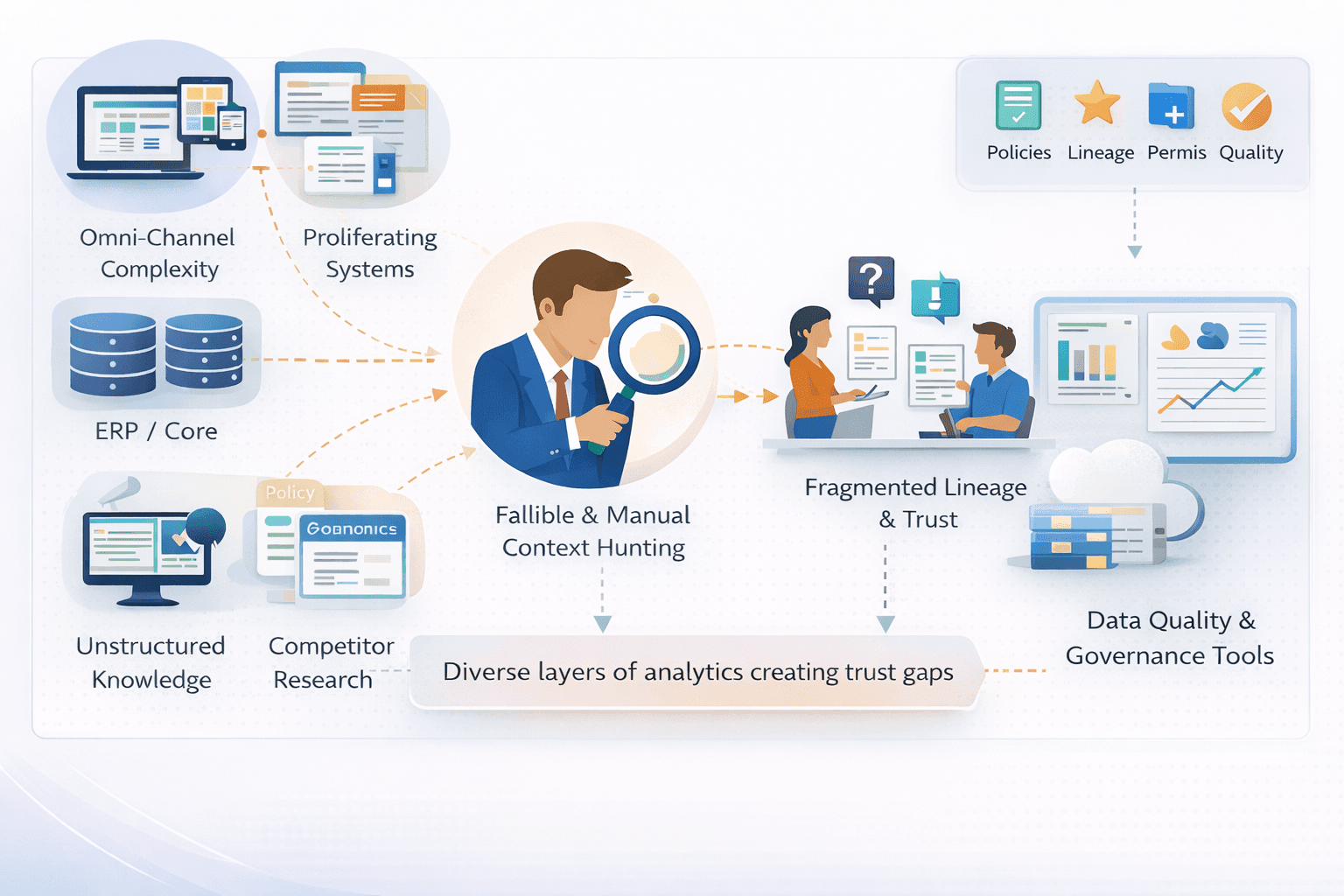
This was the time when Cloud warehouses, data lakes, and lakehouses reduced infrastructure friction and separated compute from storage — a major architectural advancement. While they improved scalability, they did not fundamentally solve reasoning. Costs also expanded with scale.
Meanwhile, unstructured data (invoices, POs, scraped web content) entered narrow transactional workflows. Yet deeper business context — SOPs, policy frameworks, regulatory documents, competitive research — remained largely outside analytical systems.
Summarising the Pre AI Era
Business Intelligence was thought of as a tool to respond to “what” – the history of business
“Why” and “how” remained human-dependent.
Massive repositories of evidence accumulated and interpretation left entirely to humans
Technology built for transactional systems was extended through patchwork layers (ETL, governance, quality) to serve analytical needs.
Unstructured data integration focused primarily on transaction processing, not reasoning.
2022+ — AI Exposes the Gap
In very simple language AI is bringing a structural shift. For the first time, business context that historically lived outside systems — policy documents, SOPs, regulatory notes, product memos, competitor research — can be computationally interpreted. This is not merely Master Data Management or semantic modeling. It is broader.
It makes “why” computationally accessible.
The gap between number and explanation — previously bridged manually by analysts — can now become part of the architecture.
We understand AI does not guarantee causal correctness. But when grounded in structured enterprise context, it can reason consistently within defined constraints. Past decisions, assumptions, and interpretations can themselves become part of the context to improve reasoning.
However, reality must be acknowledged:
AI will increase system breadth (more applications).
AI will increase data depth (more volume).
AI will increase expectations for speed and adaptability.
Today, many organizations are approaching AI as a capability upgrade, with better models on top of existing infrastructure with Smarter text to sql, agentic ETL Automation, governance agents etc. – all of this is short term patchwork on broken architecture. They do not address foundational architectural misalignment.
Relational databases, ETL-heavy systems, and governance stacks are inherently maintenance-intensive and slow to adapt. AI amplifies this friction.
Need of the Hour: The Architectural Shift
The emerging architectural shift centers around Enterprise Context.
AI’s core capability is language interpretation. For AI-driven analytics to work reliably, the enterprise must expose its context in structured form. This includes
Semantic Definitions: data structure meaning from upstream systems
Relationships: correlations across systems and entities
Logic: policy-driven KPI definitions
Governance Rules: Access, Privilege, Control, quality rules, distribution rules
Operational Metadata: quality stats, storage locations, partitions
SOPs and Assumptions: conditional operational knowledge
Business Environment: seasonality, regulatory context, competitive intelligence
The first three existed partially in lakehouse architectures. The latter components represent the structural addition.
Think of the Enterprise Context Layer as a living encyclopedia of the business: written in a form understandable by LLMs
We will not deep dive into the mechanics of using context (RAG, CoT, knowledge graphs, vector embeddings), as this article is to focus architecture
Now comes the bigger question – Does the Existing BI Stack Disappear? Not necessarily
Two potential evolutionary paths emerge:
Option 1 – API Mesh (Suitable for Smaller Enterprises)
Operational systems expose APIs.
A conversation layer consults the enterprise context to determine:
Which API to call
What data to extract
How to compute
This model works where upstream quality is manageable and system scale is limited.
Option 2: Open composable stack (Mid-to-Large Enterprises)
For larger enterprises, repeated API calls over large datasets introduce latency and operational complexity.
A composable architecture using compressed, file-based storage (lakehouse) - separated from context and compute - becomes more scalable. Metadata is orchestrated via the enterprise context layer.
What are the benefits of these models:
Deterministic BI (reports, dashboards, self-service) continues — but on modernized architecture.
Non-deterministic reasoning layers on top without rewriting pipelines.
Changes are absorbed at the context layer — not across schemas and ETLs.
Reasoning is inside business intelligence architecture within an in-house context system.
Storage costs reduce when heavy database dependency declines, creating economic room for AI token utilization
The question is no longer whether AI can generate insight. The question is whether enterprise architecture is designed to allow reasoning. The historical BI stack optimized for recording and summarizing. The AI era requires systems designed for reasoning and interpretation.